OpenMetadata production stories from OpenAI, Yelp, Rakuten & more — Learn More about Collate Summit '26 🚀
Community Case Study
How OpenAI Built Their Self-Service AI Data Agent for 3,500+ Employees on OpenMetadata
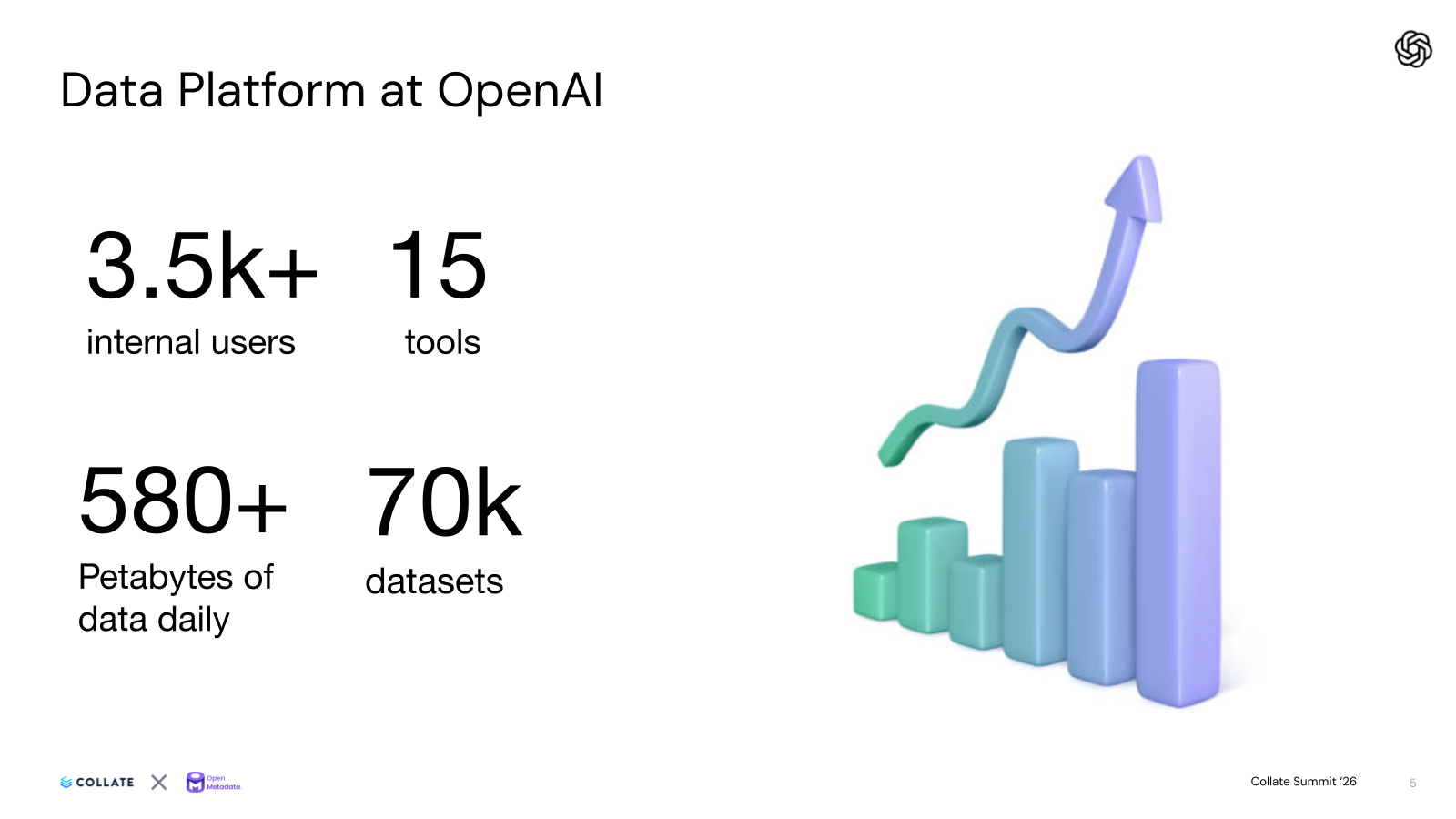
3,500+
Internal users served by Kepler, OpenAI's AI data agent built on OpenMetadata
580+ PB
Of data processed daily across 70,000 datasets
<90 sec
Time-to-answer on repeat queries, down from 22+ minutes
OpenAI's data platform serves 3,500 internal users on 15 tools, with 580+ petabytes of data processed daily across 70,000 datasets. At that scale, simple questions like "How many ChatGPT Pro users do we have in Italy?" routinely cost analysts days of table discovery, multiple code deep-dives, and several cross-team Slack threads, and could still return answers off by orders of magnitude. OpenAI's Data Productivity team built Kepler, an internal AI data agent, on top of OpenMetadata as the open context layer that grounds every response. The result: self-service analytics across the company, with repeat query runtime down from 22 minutes to under 90 seconds.
This case study is adapted from Bonnie Xu's Summit '26 keynote.
Industry
AI Research and Deployment
Technologies
OpenMetadata, Spark, Airflow, Notion, Slack, OpenAI APIs, Codex
"At that scale, the hard part is not just about finding the right table or writing SQL, it's about getting the right context, knowing what data exists, what it means, and how it relates to the business. This is where OpenMetadata has been so foundational. It's an important part of our six-layer context model so that the agent can reason more like a real analyst."
Bonnie Xu
Tech Lead, Data Productivity at OpenAI
Days of Searching, Multi-Team Threads, and Wildly Wrong Answers
Eighty percent of OpenAI's employees rely on the data platform every day. As the product scaled, so did the complexity of the questions being asked. Going from "how many users do we have?" to "how many daily active instant-checkout users do we have in New York?" scaled the cost of getting a response, as well as the difficulty of getting the answer correct. Tables proliferated, semantics drifted, and the institutional knowledge needed to use them stayed locked in Slack threads and engineers' heads.

Confidently Wrong by Orders of Magnitude
With 70,000 datasets across 15 tools, analysts faced a haystack of similar-sounding tables with subtle, consequential differences. Some tables had encrypted IDs, some didn't. Some adjusted for fraud, some didn't. Some pre-filtered for feedback, some didn't. Missing one nuance (a single column difference, a missing filter) could produce answers off by orders of magnitude. In a real life example, when asked how many ChatGPT users there are, an AI agent incorrectly answered 5,062,338. The real number: 800 million.
Simple Questions, Expensive Answers
A question that should take minutes was costing days of work across teams. A business lead would ask how many ChatGPT Pro users were in Italy. The data scientist would consult another engineer, who would consult another, who would hunt through tables. By the time the answer landed, it had taken three code deep-dives, two quick meetings, and five Slack threads. At 3,500 internal users across 15 tools, the cost of every question compounded across the whole company.
Context Trapped in Tribal Knowledge
A table's name and schema only tell part of the story. Why was it created? What filter did the analytics team apply at ingestion? What does this column mean in this team's vocabulary? That context lived in Notion docs, Slack incident channels, code review comments, and individuals' memories, invisible to any agent looking only at metadata. Without that layer, an AI agent could read the schema correctly and still give a wildly wrong answer.
No Memory Across Conversations
Without a memory layer, every correction had to be relearned. If an analyst told the agent that a particular product type was filtered by a specific value, the next query restarted from scratch. Repeat questions would cost as much time as first-time questions. Team-specific definitions, edge-case filters, and learned corrections disappeared the moment a session ended.
Sensitive Data, Permissions Needed Beyond the Table
OpenAI's data includes information that not every user should be able to see. An agent ranging across all of it had to respect who could access what, without leaking sensitive context through query history or shared chats. Permission checks needed to extend to retrieval, sanitized queries, and chain-of-thought, not just row-level table access.
An AI Data Agent on the Open Context Layer
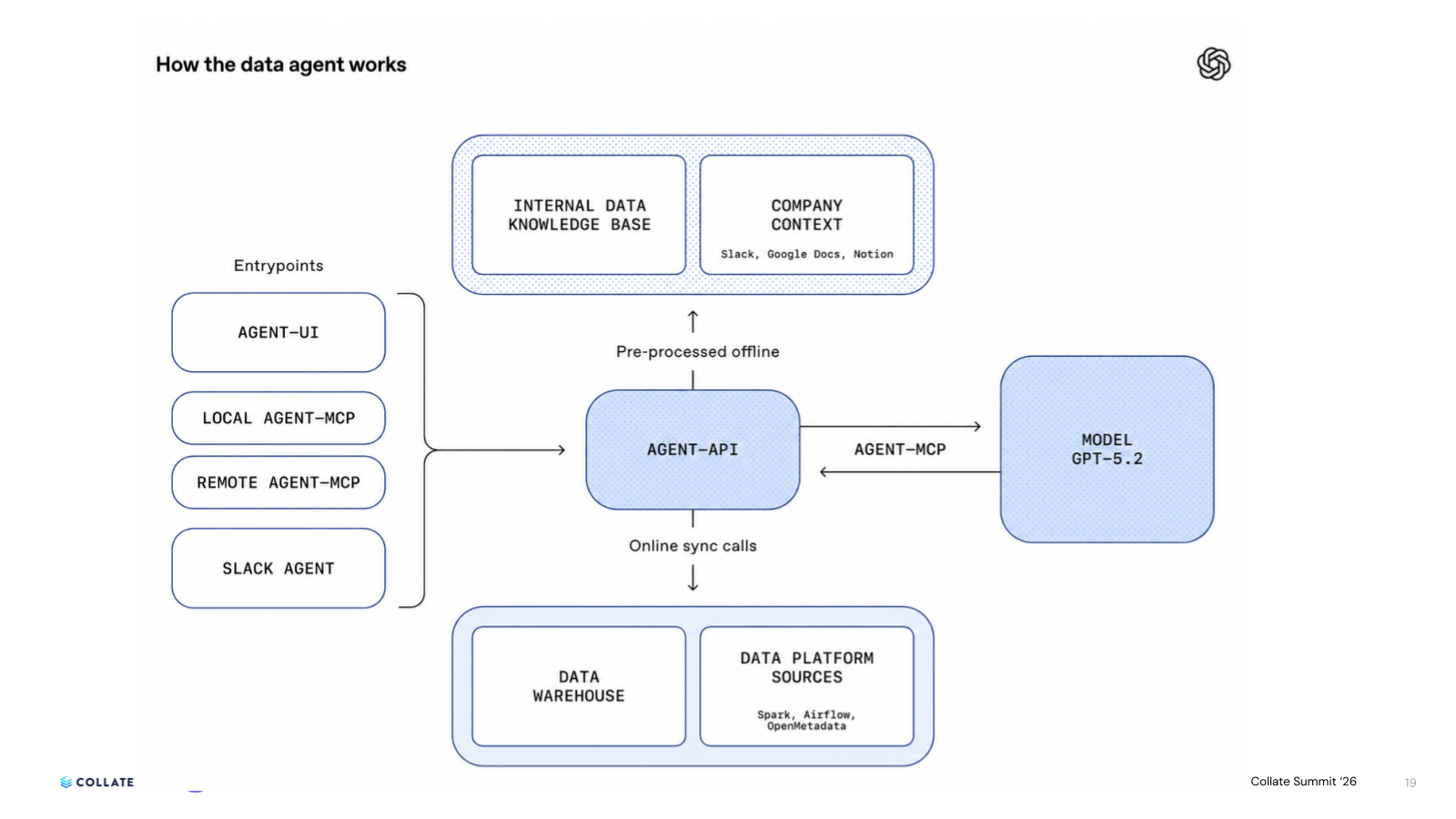
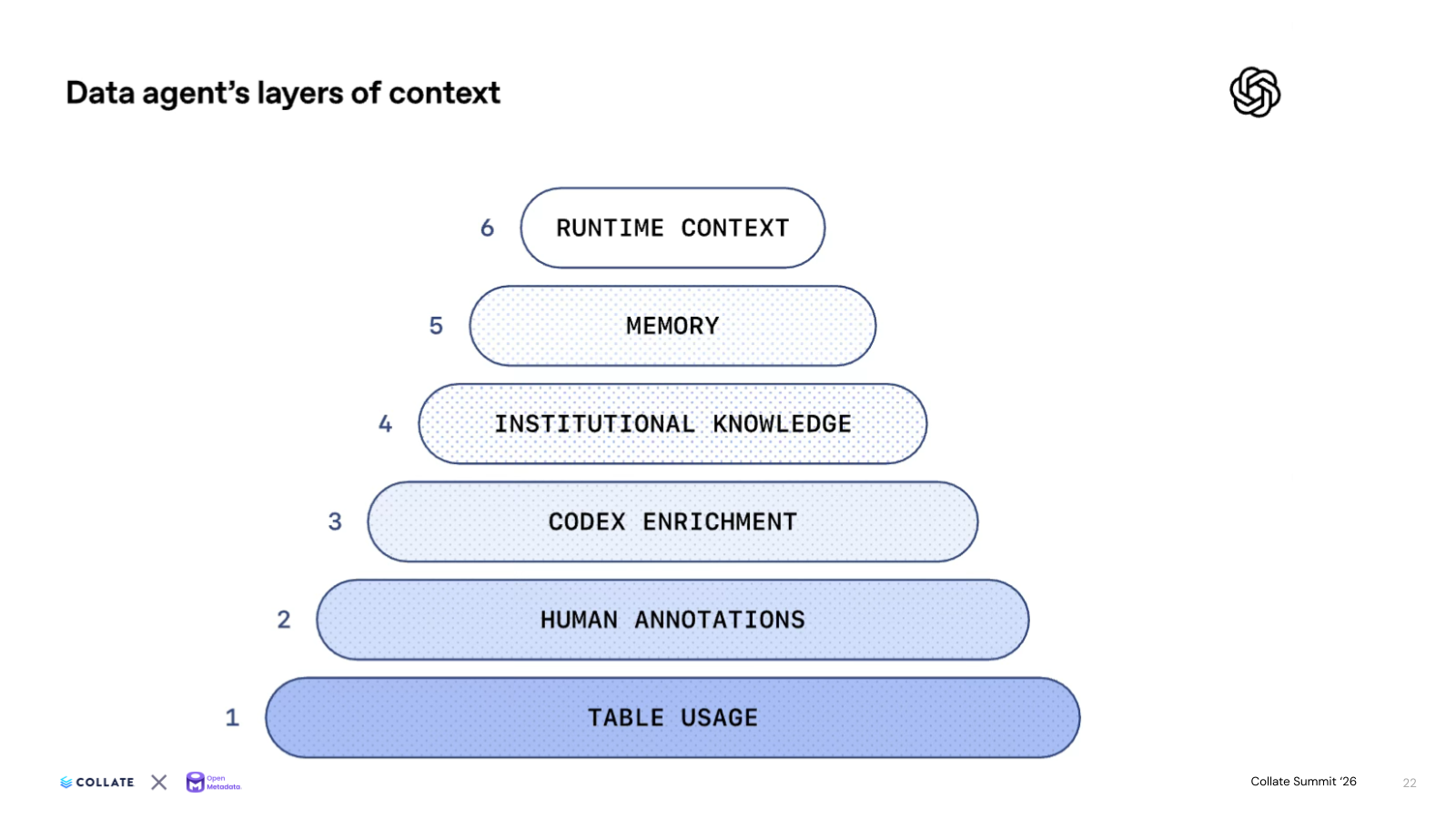
OpenAI's Data Productivity team built Kepler, an internal AI data agent designed to be surfaced wherever the work happens (Slack, the IDE, web agents, workflows) to help users answer business questions quickly. Instead of building a metadata layer from scratch, they put OpenMetadata on top of their data warehouse and let it carry the context needed by the agent to reason. The architecture organizes context into six layers that the agent draws on per query.
OpenMetadata as the Context Foundation
Kepler's first layer of context is table metadata surfaced from OpenMetadata: schemas, query history, lineage, and co-derived table information. All of it is transformed into embeddings so the agent can do semantic search and rank retrieval. The agent finds the right table by meaning, not just by matching keywords, and grounds every answer in the structural metadata organized and governed by OpenMetadata.
Human Annotations, Edited in Place
Layer two is human annotations (descriptions, tags, usage, ownership) that the data team maintains in the OpenMetadata UI. The agent reads these through OpenMetadata APIs for both offline indexing and live retrieval. Where descriptions are missing or stale, the agent auto-generates candidates the team can confirm, so the context layer improves as the agent runs.
Codex Enrichment, Institutional Knowledge, and Runtime Calls
Three more layers add additional context for understanding. Codex (OpenAI's coding agent) reads the actual pipeline code that builds each data table in offline jobs in order to explain why each table exists (purpose, downstream usage, primary keys), providing additional context to Kepler so the AI agent understands a table's true meaning, not just its name. Institutional knowledge from Slack threads and Notion docs feeds the agent permission-gated context on tribal knowledge and business meaning. Runtime calls to Spark, Airflow, and OpenMetadata fill in additional details in real time.
A Memory Layer That Compounds
The final layer is memory. As analysts use Kepler, the agent suggests memories drawn from conversations, which users can confirm. Memories can be scoped global (shared across the company) or user (personal customizations). As these memories build, the agent gets smarter every time someone corrects it. A team-specific filter learned today becomes inherited context for every query that follows.
Evals and Permission Enforcement Built In
To prevent regressions as the platform evolved, the team built an evals system using OpenAI's evals grader: SQL AST normalization, result-set comparison with reasonable tolerances, and chain-of-thought debugging. Permission checks at every layer ensure the agent only ever surfaces data the requesting user is authorized to see. Query history is sanitized so important IDs aren't leaked, gated content stays gated even when an agent chat is shared, and a user who needs a table they can't access is pointed to the right request groups in the OpenMetadata UI rather than to the data itself.
Self-Service Analytics at Enterprise Scale
Kepler now runs in production across OpenAI's data platform, available wherever employees work. Users can ask questions in plain language and get back an answer grounded in the same context a senior analyst would carry in their head: what the data means, where it came from, and which caveats apply. This understanding is baked into the context layer that anchors the AI agent, and this open foundation of OpenMetadata, is the same one that any data team can adopt.
From Multi-Day Searches to Self-Service in Minutes
Every data user at OpenAI is now empowered with a trusted AI data agent to independently ask questions and get reliable answers. Teams no longer need to route a question to a data scientist who routes it to an engineer who hunts through tables, and can now be self-serviced, leading to significant time savings and productivity gains across the organization.
Trusted Answers Grounded in Context
The agent now reasons the way a careful analyst does: investigating a March 2025 growth spike, it pulled the weekly-active-user tables for the exact numbers, cross-checked a Notion doc and a dashboard to confirm it had the right table, ruled out a logging-duplication bug, and used web search to land on the real cause of the spike, which was due to a viral image-generation trend.
Verifiable Answers, Every Time
Every response streams the agent's chain of thought, links every query it ran, and cites every assumption. Analysts can sanity-check what the agent picked, click through to raw query results, and confirm definitions before acting. Combined with the permission model (sanitized query history, gated content retrieval), the agent is auditable end-to-end at OpenAI's scale.
Repeat Queries: 22 Minutes → Under 90 Seconds
With memory compounding across conversations, repeat queries for difficult questions are accelerated for later users. Every correction a team makes (a filter, a definition, a known caveat) becomes context the next analyst (or agent) can leverage to significantly save time and effort. In one example, a query that initially took 22 minutes and 41 seconds to analyze could then be resolved in 1 minute and 22 seconds, because the agent saved corrections as memory for downstream usage.
An Open Context Layer for Every Data Team
When asked how a smaller data team should start, Bonnie's answer was three lines: leverage existing APIs (OpenAI Responses, embeddings, evals); use Codex to iterate quickly; and use OpenMetadata for the context layer. The OpenMetadata foundation OpenAI selected for Kepler is the same open standard available to any team that wants to ship an AI data agent on a context layer they own, without any proprietary lock-in.
